Logical Neural Networks
From Deep Learning to Deep Thinking
Ryan Riegel, Francois Luus, and Alexander Gray
Neuro-symbolic AI
Neuro-symbolic AI systems aim to bridge the gulf that presently exists between two of AI’s most studied disciplines: principled, deductive inference via any of various systems of formal logic, and data-driven, gradient-optimized neural network architectures. Both paradigms bear a number of important strengths and weaknesses. Notably, formal logic is interpretable, verifiable, and broadly generalizable even to novel tasks, though it is computationally intensive if not undecidable, requires extensive domain expert input, and can be derailed by even minor inconsistencies. Neural networks, on the other hand, perform well even for unprocessed and/or noisy data, require little human configuration, and can run efficiently in parallel. Their downsides, however, are their extreme data requirements, their vulnerability to adversarial attack, and their uninterpretable black-box nature.
It is believed that, by merging the two disciplines, it may be possible to exploit either’s strengths while mitigating their weaknesses. Numerous efforts have been made to bridge the two comprising a number of different strategies. Early works established that neurons could be constrained to act as logical operations [1] and could be connected to form recurrent feed-forward networks capable of inference with Horn clauses and other simple formulae [2]. More recent work has explored undirected inference, e.g. modus tollens in addition to the more familiar modus ponens, via restricted Boltzmann machines [3]. In another vein, various groups have “softened” more traditional theorem proving techniques with neural formulations [4, 5, 6] while others have employed tensorization and relational embeddings to perform first-order logic knowledge completion [7] and rule induction [8].
Most of the above have, either implicitly or explicitly, deferred to some form of real-valued logic as a proxy for classical logic and, in addition, some establish a notion of probability weights on formulae, though in either case the impact on logical soundness is largely unstudied. Few have been tested on problems larger than toy examples (in some cases due to computational infeasibility), and none quite offers the holy grail of neuro-symbolic fusion: interpretable, verifiable neural networks, informed by any available domain knowledge but resilient to inconsistency, able to exploit Big Data but competent even in its absence.
Overview
We have developed a novel representation, the Logical Neural Network (LNN) [9], which is simultaneously capable of both neural network-style learning and classical AI-style reasoning. The LNN is a new neural network architecture with a 1-to-1 correspondence to a system of logical formulae, in which neurons model a rigorously defined notion of weighted real-valued or classical first-order logic. This idea was arguably already inherent in the thinking of the very first paper on artificial neural networks [10], in which McCulloch and Pitts proposed that the basic neuronal units of the brain could be thought of as logical gates. Subsequent authors, however, did not pursue this interpretation to a significant degree and have instead focused on other aspects, ultimately leading to modern Deep Learning.
It is well-known that standard, weighted artificial neurons can act like logical gates such as “AND” or “OR” for certain settings of the weights. Running with this idea, LNN makes use of a neural network structure similar to that of KBANN [1] or CILP [2], in which each neuron represents a piece of a logical statement — either a logical connective (e.g. “AND” or “OR”, as noted) or a concept (e.g. a node in a knowledge graph) — as shown in Figure 1.

Like KBANN and CILP, LNN’s neurons are arranged according to the syntax trees of a system of logical formulae which is given by the domain knowledge provided as input. LNN goes beyond these earlier neuro-symbolic methods, however, in that it:
1. Permits training while preserving the classical or real-valued nature of its logical gates by enforcing certain logical constraints on neural weights during training,
2. Performs omnidirectional inference, propagating truth values both from each formula’s atoms to its root and vice versa, thereby modeling classical inference rules such as modus ponens, modus tollens, and conjunctive syllogism, among others, and
3. Maintains both lower and upper bounds on truth values at each of its neurons, i.e. logical subformulae, thereby allowing the open-world assumption that some logical statements may be true even if their truth is not known or provable.
Even considering these innovations, LNNs remain a special case of normal neural networks, and are in fact implementable in standard frameworks such as PyTorch. LNNs can perform supervised classification, just as a standard neural network can — in LNNs, the training data are represented as atomic facts (typically leaf nodes) which are instances of more abstract predicates (typically internal nodes), and the class being predicted is the truth value of a node representing the hypothesis of the class variable being set to a certain value. Training consists of an optimization, as in a standard neural network, but includes constraints on weights to enforce the logical meaning of nodes, and uses a novel loss function which mininimizes logical contradiction, or maximizes internal logical consistency. Instead of the layers of a standard neural network, in LNNs the nodes are derived from a set of logical statements — the most common natural source of such statements is a knowledge graph such as DBpedia, which is a collection of statements in a description logic. (Additional nodes which do not have any known meaning can also be added to an LNN in principle; we will explore this more fully in future work.)
Due to their 1-to-1 correspondence with systems of logical formulae, an LNN can also be viewed precisely as a collection of logical statements in real-valued logic (where truth values are not restricted to just 0 and 1 but can lie anywhere in between). In a separate, very fundamental work [11] we have shown that the larger class of logics to which LNN belongs is capable of sound and complete (i.e. correct and thorough) reasoning, to the same degree as has been shown for classical logic [ref: real-valued logic foundations blog].
Thus, like the famous ‘wave-particle duality’ of physics, LNNs can simultaneously be seen entirely as neural nets and entirely as sets of logical statements, and thus able to leverage the capabilities of both the statistical AI and symbolic AI worlds.
Main idea #1: Logical constraints
Our first main idea is the use of constrained optimization during learning to guarantee logical behavior of all neurons in an LNN.
Before we can discuss LNNs further, it is necessary to develop an understanding of the computations their neurons perform. The output of a logical neuron is computed much the same as it is for any neuron by applying some nonlinear activation function f : ℝ → [0, 1] to a linear combination of its inputs w · x − θ for an input vector x, weight vector w, and activation threshold θ, as shown in Figure 2. Different from other neural nets, however, is that LNN’s neural parameters are constrained such that neurons behave according to their corresponding logical gates’ truth functions.
For instance, consider a selected threshold of truth α, such that neural inputs and outputs are considered “true” if greater than α and “false” if less than 1 − α. Then, a conjunction neuron must return false, i.e. less than 1 − α, if even one of its inputs is similarly less than 1 − α. On the other hand, the same neuron must return true, i.e. greater than α, if all of its inputs are similarly greater than α. We can achieve this by imposing linear constraints on neural weights and thresholds while learning, as further shown in Figure 2.

It is not difficult to see how to adapt such constraints to disjunctions and implications using the familiar tautologies (x ∨ y) = ¬(¬x ∧ ¬y) and (x → y) = (¬x ∨ y), where negation is defined ¬x = 1 − x. The choice of f affects which logic the LNN implements. Example such functions include the unit-clamped rectified linear unit (ReLU-1) f(x) = max{0, min{1, x}}, which yields a weighted form of Łukasiewicz logic, and the logistic function, which yields a smoothed form of said.
Constrained with sufficient penalty, a trained such model is guaranteed to converge on classical inference behavior. With looser constraints it is able to handle incomplete formulae, minor contradictions, and other sources of uncertainty in the ground truth.
First-order logic
Only a few changes are necessary to extend the above to first-order logic (FOL). Notably, neurons are understood to operate on and return tensors of truth values pertaining to all possible groundings, or free variable assignments, of their respective subformulae or predicates. Computations are then performed elementwise, joining inputs along tensor dimensions pertaining to the same logical variable, e.g. X in P(X) ∧ Q(X).
FOL LNN must also introduce universal and existential quantifiers as neurons that reduce tensors via min and max, respectively, over the indicated logical variables. Lastly, FOL LNN implements FOL functions and equality as specialized predicates.
Main idea #2: Omnidirectional inference
Our second main idea is to use neurons’ functional inverses to permit inference to flow in any direction through a formula’s connectives, thereby allowing it to prove facts about its inputs.
It is easy to see that the usual, feed-forward evaluation of neurons using the activation functions described above will result in truth values computed at each subformula based on known truth values for their various atoms, but this is not sufficient for logical reasoning in general. While feed-forward evaluation is typical for other neural networks, which only aim to predict one or a few pre-selected values given a collection of inputs presumed always to be available, logical inference can deduce truth values for potentially any statement via a chain of reasoning that can start from any set of other statements. This summarizes the task generality inherent in classical AI theorem proving systems, which simple supervised learning systems typically lack.
For example, a formula like x ∧ y can obviously be evaluated in an ‘upward’ direction given the truth values of x and y. On the other hand, it is also meaningful to assume x ∧ y to have truth value, e.g., 0 and then use that fact to prove truth values for either of x or y based on the other. Where classical logic uses inference rules to achieve this (in this case modus ponendo tollens, which holds that if x and y are not both true, but x is true, then y must be false), we observe that LNN’s real-valued neurons may do the same using the functional inverse of their activation functions, as shown in Figure 3. We call this downward inference in reference to the downward flow of inferred truth values through the graphical representation of a formula’s syntax tree.
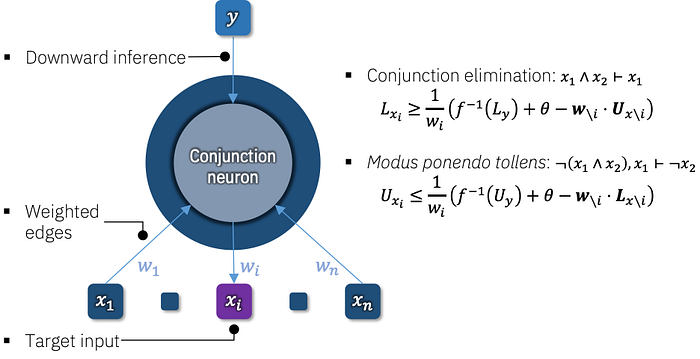
This immediately suggests a simple overall recurrent algorithm for inference that, at each iteration, computes truth values at each subformula in an upward pass and then propagates them back to each atom using downward inferences.
A minor caveat exists, however, in the fact that the functional inverse of f may be undefined or overly extreme in some regions, in particular in regions where f returns values close or equal to 0 or 1. This is in fact the motivation for our next main idea.
Main idea #3: Bounds on truth values
Our third main idea is to work in terms of lower and upper bounds on truth values, thereby permitting an elegant representation of uncertainty in light of the open-world assumption.
Rather than individual truth values (or tensors of truth values in the FOL case), each neuron in an LNN keeps both a lower and upper bound truth value for its corresponding subformula or atom. In addition to assisting with the caveat mentioned for omnidirectional inference, this permits the explicit handling of the open-world assumption by initializing unknown facts with lower bound L = 0 and upper bound U = 1. Unlike other neuro-symbolic methods, which always return some one truth value for a particular query, effectively assuming that the query’s truth can be known, LNN is free to leave these loose, thereby modeling uncertainty as distinct from known contradiction (L > U) and known ambiguity (e.g. L = U = .5).
Revisiting the caveat for f with undefined or extreme functional inverse near 0 or 1, consider f(x) = max{0, min{1, x}} for a neuron modeling A → B. For one possible configuration of the weights, such a neuron may have activation function and inverse (used for modus ponens, which holds that if A implies B, and A is true, the B must also be true) as shown in Figure 4.
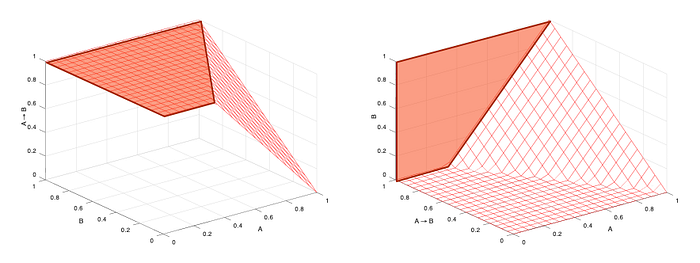
The highlighted regions of these plots correspond to the same plane: all combinations of A and B yielding (A → B) = 1. This constitutes a discontinuity in the inverse. As suggested, we handle this by considering lower and upper bounds separately, in this case conditionally returning just 1 for the upper bound of B when (A → B) = 1.
Intuitively, this lets modus ponens and related rules return loose results as appropriate, even when their inputs are otherwise known exactly. For example, in classical logic, if A → B is true but A is false, then we can’t say one way or the other about B. Just as well, in the real-valued case, if (A → B) = 1 and, say, A = .6, then for the shown weights all we can say is that B ∈ [.4, 1]. On the other hand, if (A → B) = .8, then we know B = .2 exactly.
One might ask, however, what if no value of B ∈ [0, 1] can satisfy a particular combination of A and A → B, or any other operator for that matter? The result is a contradiction, but unlike other theorem provers, LNN handles these elegantly and can in fact make use of them in learning.
Learning
It is possible to translate an existing KB directly into an LNN using, for example, weights all equal to 1 and thresholds equal to 0 for disjunctions and n − 1 for conjunctions. Even without subsequent training, such a network would be able to perform useful inference. On the other hand, presented with ground truth observations, constrained optimization can tune the network to become more tolerant of corner cases and noisy data.
Logical loss
Like most neural networks, LNNs may be trained with a plethora of different loss functions, though these mostly focus on minimizing some measure of error when making predictions, e.g. mean-square error. Unlike other neural networks, however, LNNs may also explicitly learn to avoid logical inconsistency by incorporating a contradiction term into their loss function. Such a term is characterized by the extent to which each neuron’s lower bound truth value exceeds its upper bound, summed over all neurons and averaged over all training examples, and as such constitutes a form of hinge loss.
The above are linear constraints and may thus be used in conjunction with methods such as Frank–Wolfe to train an LNN’s weights, however, a number of issues remain that must be addressed before training can be practical. In particular, the constraints shown in Figure 2 do not permit weights to drop to 0, thereby effectively removing their inputs, and gradient quality can be poor for certain choices of f. Various improvements to the optimization procedure can mitigate these, such as the inclusion of slack variables and the use of activation functions comparable to leaky ReLUs.
Further reading
In the paper [9], we describe mathematical details including the optimization problem implementing learning, the inference procedure and its convergence, and LNN’s inherent self-explainability. We also provide empirical comparison to previous neuro-symbolic frameworks, including Logic Tensor Networks [7] and Markov Logic Networks [12], along the axes of interpretability, theorem-proving effectiveness, and ability to handle imperfect knowledge.
In separate work [11], we show that the logic implemented by LNNs has a sound and complete axiomatization even when formulae are permitted to have truth values other than exactly 1, a first among the well-studied field of real-valued logics.
References
1. Towell, Geoffrey G., and Jude W. Shavlik. “Knowledge-based artificial neural networks.” Artificial Intelligence 70.1–2 (1994): 119–165.
2. Garcez, Artur S. d’Avila, and Gerson Zaverucha. “The connectionist inductive learning and logic programming system.” Applied Intelligence 11.1 (1999): 59–77.
3. Tran, Son N. “Propositional knowledge representation in restricted boltzmann machines.” CoRR (2017).
4. Rocktäschel, Tim, and Sebastian Riedel. “Learning knowledge base inference with neural theorem provers.” Proceedings of the 5th Workshop on Automated Knowledge Base Construction. 2016.
5. Yang, Fan, Zhilin Yang, and William W. Cohen. “Differentiable learning of logical rules for knowledge base reasoning.” Advances in Neural Information Processing Systems. 2017.
6. Evans, Richard, and Edward Grefenstette. “Learning explanatory rules from noisy data.” Journal of Artificial Intelligence Research 61 (2018): 1–64.
7. Serafini, Luciano, and Artur d’Avila Garcez. “Logic tensor networks: Deep learning and logical reasoning from data and knowledge.” arXiv preprint arXiv:1606.04422 (2016).
8. Dong, Honghua, et al. “Neural logic machines.” arXiv preprint arXiv:1904.11694 (2019).
9. Riegel, Ryan, et al. “Logical Neural Networks.” arXiv preprint arXiv:2006.13155 (2020).
10. McCulloch, Warren S., and Walter Pitts. “A logical calculus of the ideas immanent in nervous activity.” The bulletin of mathematical biophysics 5.4 (1943): 115–133.
11. Fagin, Ronald, Ryan Riegel, and Alexander Gray. “Foundations of Reasoning with Uncertainty via Real-valued Logics.” arXiv preprint arXiv:2008.02429 (2020).
12. Richardson, Matthew, and Pedro Domingos. “Markov logic networks.” Machine learning 62.1–2 (2006): 107–136.